
Một bài viết nhấn mạnh sự quan trọng của việc đặt ra những nguyên tắc và quy định cơ bản trong quá trình phát triển trí tuệ nhân tạo
Trí tuệ nhân tạo, trước đây được coi là lĩnh vực độc quyền của những người am hiểu công nghệ, hiện đang trở thành một công cụ được sử dụng rộng rãi để nâng cao năng suất. Bỏ qua tác động của trí tuệ nhân tạo đối với các ứng dụng và quy trình cốt lõi của doanh nghiệp có thể rất nguy hiểm.
Trong một khảo sát với 600 CIO và các nhà lãnh đạo công nghệ khác do MIT Technology Review Insights tiến hành, chỉ có 6% hoặc ít hơn cho biết công ty của họ không sử dụng trí tuệ nhân tạo hiện nay. Ngày nay, người tiêu dùng tham gia hàng ngày vào các giao dịch được hỗ trợ bởi trí tuệ nhân tạo để hoàn thành các nhiệm vụ thông thường như đặt vé du lịch, quản lý tài chính và mua sắm trực tuyến.
Trí tuệ nhân tạo đã trở thành nên phổ biến, nhưng các vấn đề và tác động liên quan đến việc sử dụng nó cũng vậy. Các công ty áp dụng trí tuệ nhân tạo đối mặt với các yêu cầu pháp lý và quy định mới nổi, cũng như sự không tin tưởng, thậm chí là sợ hãi, đối với trí tuệ nhân tạo từ phía người tiêu dùng. Mô hình trí tuệ nhân tạo càng lớn, càng cần hiểu rõ sự giám sát của con người và đạo đức trong quá trình phát triển thuật toán.
Các công ty phát triển trí tuệ nhân tạo cần đảm bảo nguyên tắc và quy trình cơ bản đã được thiết lập để đạt được trí tuệ nhân tạo có trách nhiệm. Điều này là một yêu cầu để đảm bảo sự phát triển liên tục tuân thủ quy định, sự tin tưởng cao hơn vào trí tuệ nhân tạo từ phía khách hàng và công chúng, cũng như tính toàn vẹn của quá trình phát triển trí tuệ nhân tạo. Tiếp tục đọc để tìm hiểu tại sao điều này quan trọng và xem xét các giá trị mà công ty của bạn nên cố gắng gắn kết, cả trong các thực tiễn làm việc và trong những người thực hiện chúng.
Điều gì dẫn chúng ta đến vấn đề này?
Để hiểu được khả năng mà các tổ chức cần phải tạo ra và vận hành trí tuệ nhân tạo một cách có trách nhiệm, trước tiên chúng ta cần hiểu tại sao và làm thế nào việc sử dụng trí tuệ nhân tạo đã trở thành một điều cần được bàn luận.
- Không coi trọng pháp luật. Trong quá khứ, các tổ chức đã sử dụng trí tuệ nhân tạo theo cách vi phạm pháp luật, hoặc làm phương tiện để vượt qua các hạn chế pháp lý. Cũng có các ứng dụng trí tuệ nhân tạo (như deepfakes) có nhiều ứng dụng đáng nghi ngờ.
- Sự đa dạng về giá trị. Một số mẫu hành vi được coi là công bằng và đạo đức bởi một nhóm, trong khi đối với nhóm khác, chúng lại không tương thích. Do đó, các ứng dụng trí tuệ nhân tạo có thể hoạt động một cách không tuân thủ đạo đức theo góc nhìn của một nhóm khác, trong khi lại hoàn toàn đạo đức theo quan điểm của nhóm đã thiết kế chúng. Công chúng coi đây là một vấn đề kỹ thuật của trí tuệ nhân tạo và không phân biệt với các trường hợp khác khi trí tuệ nhân tạo có kết quả không đạo đức, dẫn đến sự không tin tưởng vào trí tuệ nhân tạo.
- Thiếu tính mạnh mẽ. Các tổ chức đã phát triển các ứng dụng trí tuệ nhân tạo không đủ mạnh mẽ để chống lại việc sử dụng không đúng mục đích, ví dụ như:
- Sự không hiểu giới hạn (và mục đích) của trí tuệ nhân tạo của trẻ em hoặc các nhóm người khác.
- Người dùng có ý đồ độc hại cung cấp dữ liệu không tốt hoặc phản ứng với một thiết bị thay vì một người.
Ngoài ra, trí tuệ nhân tạo có thể có lỗi hoặc lỗ hổng bảo mật giống như các ứng dụng công nghệ thông tin khác có thể dẫn đến hành vi gây hại không cố ý.
- Dữ liệu thiên vị. Khi thuật toán học từ dữ liệu huấn luyện, có nhiều loại thiên vị trong dữ liệu huấn luyện có thể dẫn đến kết quả không đúng ý. Ví dụ, với các thuật toán học từ các quyết định trước đó của con người, AI cũng sẽ học và áp dụng một cách thiên vị.
- Thiếu tính minh bạch. Ngay cả khi kết quả của một thuật toán có vẻ công bằng và không thiên vị, việc không thể giải thích kết quả của một trường hợp cụ thể sẽ gây ra sự thiếu tin tưởng, đặc biệt là đối với các bên liên quan chịu ảnh hưởng tiêu cực. Nếu nguồn gốc của kết quả không được biết đến, cũng khó để chứng minh rằng nó không phân biệt đối xử quá mức đối với một đặc điểm cụ thể của một cá nhân.
Giải pháp: Áp dụng trí tuệ nhân tạo có trách nhiệm
Các doanh nghiệp cần sử dụng trí tuệ nhân tạo mà họ có thể tin tưởng được. Họ cần biết rằng quyết định của trí tuệ nhân tạo tuân thủ pháp luật và phù hợp với giá trị của họ. Nếu các hệ thống trí tuệ nhân tạo – và những con người đứng sau chúng – không đáng tin cậy một cách rõ ràng, những hệ quả không mong muốn xảy ra, sự kháng cự tăng lên, cơ hội phát triển bị bỏ lỡ và, có thể, danh tiếng bị tổn hại.
Tuy nhiên, quá nhiều khi đưa trí tuệ nhân tạo trở nên có trách nhiệm chỉ là một suy nghĩ sau cùng đối với nhiều tổ chức. Ban đầu, họ tập trung hơn vào xác định các trường hợp sử dụng ảnh hưởng cao để áp dụng trí tuệ nhân tạo mà không quan tâm đến các vấn đề đạo đức. Tiếp theo, họ triển khai các giải pháp trí tuệ nhân tạo dựa trên chính sách hiện có của công ty, mà không xem xét liệu chúng có đủ cho mục đích hay cần được điều chỉnh hay không. Cuối cùng, khi trí tuệ nhân tạo kết quả lại mang lại những kết quả tiêu cực, họ đặt dấu hỏi về chức năng và giá trị tổng thể của trí tuệ nhân tạo và chỉ sau đó mới xem xét khả năng “tạo” trí tuệ nhân tạo có trách nhiệm sau sự việc. Điều này dẫn đến các nguyên tắc mới, các quy định, các quyết định tòa án và các hình thức bình thường hóa khác cuối cùng quay trở lại việc phát triển các mô hình và giải pháp trí tuệ nhân tạo hoàn toàn mới.
Đạo đức và tuân thủ không nên chỉ là suy nghĩ sau cùng; các công ty nên “làm đúng” ngay từ đầu. Việc sử dụng trí tuệ nhân tạo một cách đạo đức và tuân thủ phải trở thành một phần không thể tách rời trong DNA ML/AI của tổ chức. Cách tốt nhất để làm điều này là thiết lập, tối giản, những nguyên tắc hướng dẫn cơ bản và khả năng quản lý cho quá trình phát triển trí tuệ nhân tạo.
1. Đảm bảo sự phù hợp với giá trị đạo đức.
Các tổ chức nên rõ ràng xác định và truyền đạt các giá trị, luật pháp và quy định trong hoạt động của họ, và các mẫu hành vi (của ứng dụng) mà họ xem là công bằng và đạo đức trong khung việc có sử dụng trí tuệ nhân tạo. Ít nhất, khung việc này nên cung cấp các nguyên tắc hướng dẫn rõ ràng về cách các quy trình AI đáp ứng những tiêu chuẩn này:
- Mọi việc sử dụng AI phải tuân thủ luật pháp.
- AI phải tôn trọng quyền riêng tư dữ liệu.
- Nguy cơ từ việc sử dụng AI đối với doanh nghiệp phải được nghiên cứu và giảm thiểu.
- Tác động xã hội từ việc sử dụng AI phải được hiểu rõ.
- AI phải rõ ràng tự xưng là AI và không giả vờ là con người.
Là một phần của “văn hóa sử dụng có trách nhiệm,” tất cả các thành viên cũng nên đồng ý rằng họ sẽ không sử dụng AI:
- Vượt ra ngoài những gì đã được chứng minh là hoạt động đúng.
- Cho các mục đích khác ngoài những gì đã được đồng ý.
- Cho các mục đích có thể được coi là không đạo đức một cách khách quan.
2. Áp dụng sự chịu trách nhiệm qua cơ cấu tổ chức
Cơ cấu tổ chức cho quản trị AI nên được xác định và được duy trì. Trong đó, các vai trò và trách nhiệm cụ thể nên được giao cho cá nhân ở mọi cấp độ trong tổ chức để thiết lập sự chịu trách nhiệm trong quá trình phát triển và sau quá trình phát triển AI. Dưới đây là một ví dụ.
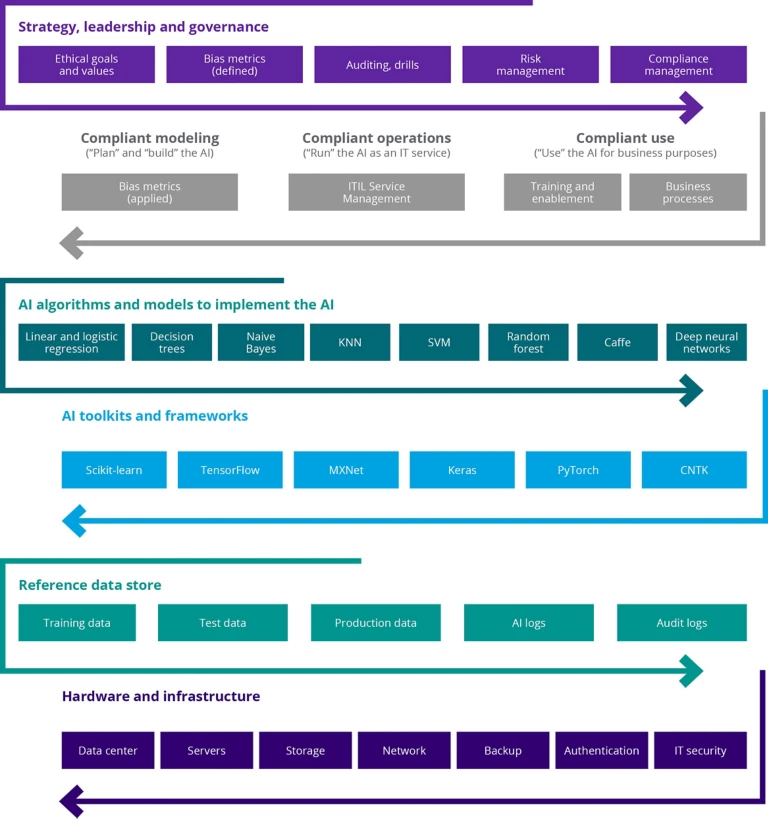
Các nhiệm vụ cụ thể của các cá nhân có thể bao gồm:
- Thực hiện khung pháp lý AI có trách nhiệm, tuân thủ các tiêu chuẩn của tổ chức. Lưu ý: Những cá nhân này cũng có thể là người tư vấn và trọng tài trong trường hợp có sự nghi ngờ hoặc bất đồng quan điểm về việc tuân thủ của một dự án AI cụ thể.
- Xác định và giảm thiểu (thực hiện biện pháp khắc phục) các rủi ro liên quan đến AI cụ thể.
- Tiến hành kiểm thử và phân tích đầy đủ của AI, cũng như theo dõi liên tục.
Cũng cần có sự thông tin rõ ràng đến các nhà phát triển, những người kiểm thử, quản lý của họ, chủ dự án/sản phẩm và các bên liên quan khác về các yêu cầu và các quy tắc tốt nhất được mong đợi từ họ
3. Giảm thiểu rủi ro và tăng cường khả năng phục hồi
Sự mạnh mẽ của một hệ thống kỹ thuật chung là khả năng chịu đựng các sự cố. Các hệ thống AI phải được phát triển sao cho chúng hoạt động đáng tin cậy và như mong đợi, tạo ra kết quả chính xác và chống lại các mối đe dọa từ bên ngoài.
Một hệ thống AI, giống như bất kỳ hệ thống IT nào khác, có thể bị tấn công bởi những cuộc tấn công đối thủ. Ví dụ, các hacker nhắm mục tiêu dữ liệu (“làm ô uế dữ liệu”) hoặc cơ sở hạ tầng cơ bản (cả phần mềm và phần cứng) có thể khiến AI ra quyết định hoặc phản ứng khác nhau hoặc hoàn toàn tắt máy. Thông tin tiết lộ về hoạt động của một mô hình AI cho phép các tấn công viên sử dụng AI với dữ liệu được chuẩn bị một cách đặc biệt để tạo ra một phản ứng hoặc hành vi cụ thể.
Dữ liệu không công bằng hoặc không đủ cũng có thể tạo ra AI không đủ mạnh mẽ cho nhiệm vụ của nó. Trên thực tế, bất kỳ độ lệch nào trong AI đều có thể được coi là gây ra hành vi không mạnh mẽ, vì sự thiếu độ lệch và công bằng là yêu cầu thiết kế điển hình cho một AI.
Để cải thiện tính mạnh mẽ của AI của bạn, chúng tôi đề xuất thực hiện những biện pháp sau:
- Dự đoán các cuộc tấn công tiềm năng. Xem xét các loại tấn công khác nhau mà hệ thống AI có thể bị tổn thương (ví dụ: ô uế dữ liệu, cơ sở hạ tầng vật lý, tấn công mạng) và kiểm tra AI một cách kỹ lưỡng trong các điều kiện và môi trường khác nhau. Điều này sẽ giúp AI trở nên linh hoạt với các thay đổi trong môi trường hoạt động và kháng lại các loại tấn công được dự đoán.
- Xem xét sự sử dụng song song. Xem xét mức độ mà hệ thống AI có thể được sử dụng song song.
- Đánh giá các rủi ro. Đo và đánh giá các rủi ro và an toàn, đặc biệt là rủi ro đối với tính mạng và thể chất của con người.
- Phân tích các vấn đề về bảo mật hoặc mạng lưới. Xác định xem, ví dụ, các nguy hiểm về an ninh mạng có thể gây ra rủi ro an toàn hoặc thiệt hại do hành vi không cố ý của hệ thống AI.
- Theo dõi và kiểm tra. Ghi lại và thực hiện quy trình kiểm tra và xác nhận tính đáng tin cậy của hệ thống AI. Kiểm tra hệ thống đều đặn để xác định xem AI có đáp ứng được mục tiêu, mục đích và việc sử dụng dự định của nó không.
- Tạo kế hoạch phụ trợ. Quyết định các hành động cần thực hiện nếu AI gặp phải các cuộc tấn công thù địch hoặc các tình huống không mong đợi khác, ví dụ: chuyển từ quy trình dựa trên thống kê sang quy trình dựa trên quy tắc hoặc yêu cầu một người điều hành con người phê chuẩn trước khi tiếp tục hoạt động.
- Ghi lại sự cố. Ghi lại các trường hợp mà hệ thống AI gặp sự cố trong các loại cài đặt cụ thể.
4. Phát hiện và khắc phục sự thiên vị
Để AI được coi là đạo đức, các bên liên quan phải tin tưởng rằng AI đưa ra các quyết định mà xã hội coi là đạo đức và công bằng – không chỉ đúng theo luật pháp hoặc được cho phép bởi một chuẩn mực đạo đức. Một khía cạnh quan trọng trong việc này là các quyết định và hành vi của AI được xem là không thiên vị. Tất nhiên, định kiến con người có thể dẫn đến các quyết định thiên vị, và AI không thể phân biệt được đâu là khả năng phán đoán chính xác của con người và đâu là định kiến. Do đó, nếu được huấn luyện với dữ liệu thiên vị (đầu vào), AI sẽ học để lặp lại định kiến con người và đưa ra các quyết định thiên vị (đầu ra). Hãy xem biểu đồ dưới đây:
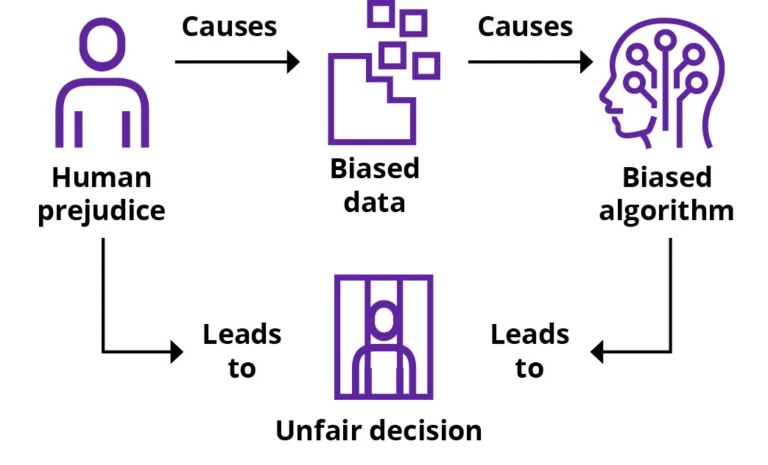
Định kiến của con người không phải là nguyên nhân duy nhất dẫn đến thiên vị. Thiên vị trong dữ liệu huấn luyện cho AI là một nguyên nhân phổ biến và điển hình cho việc hành vi của AI bị đánh giá là không công bằng bởi các bên liên quan. Dữ liệu có thể bị thiên vị bởi “các yếu tố không biết.” Vì vậy, quan trọng là phát triển cách phát hiện thiên vị và thiết lập các quy trình để giảm thiểu nó.
Không có phương pháp chắc chắn để phát hiện tất cả thiên vị trong dữ liệu huấn luyện và kiểm tra của bạn, nhưng nó bắt đầu bằng việc hiểu cách một mẫu dữ liệu cụ thể đã được thu thập và xem liệu các loại thiên vị cụ thể có thể đã xuất hiện trong mẫu đó. Hãy kiểm tra cẩn thận các phương pháp lấy mẫu dữ liệu của bạn để tìm hiểu về các loại và nguyên nhân thiên vị đã biết và xem xét lại sau này khi có nhiều thông tin hơn hoặc được tiết lộ.
Việc đặt những câu hỏi sau có thể cung cấp cái nhìn về nguyên nhân gốc rễ của thiên vị và thậm chí đề xuất một giải pháp:
Dữ liệu có đại diện cho dân số mà AI sẽ phục vụ không? Ví dụ, nếu bạn phát triển một AI để phục vụ sinh viên đại học, dữ liệu huấn luyện và kiểm tra nên đại diện cho dân số sinh viên, chứ không phải dân số tổng quát. Cần phải cẩn trọng với dữ liệu kiểm tra và huấn luyện từ quá khứ, vì nó có thể có sự thiên vị từ quá khứ. Trong ví dụ về dân số sinh viên, dữ liệu sinh viên từ quá khứ có thể quá đại diện cho sinh viên da trắng và nam giới so với dân số sinh viên hiện đại.
Dữ liệu huấn luyện và kiểm tra có bao gồm đủ đa dạng các trường hợp? Ví dụ, bạn có thể có ý định xây dựng dữ liệu huấn luyện và kiểm tra từ một phần dân số dễ tiếp cận, nhưng điều này sẽ gây ra “thiên vị lựa chọn” nếu sau này bạn muốn chạy máy tính của mình trên dân số tổng quát. Một trường hợp cực đoan của điều này là tự lựa chọn, tức là khi dữ liệu huấn luyện và kiểm tra dựa trên những người tự nguyện tham gia vào bài tập huấn luyện. Tự lựa chọn hầu như chắc chắn sẽ dẫn đến các mẫu dữ liệu không đại diện.
Có bất kỳ biến dự đoán nào mà bạn loại bỏ khỏi mô hình và thực sự không liên quan? Có thể có một mối quan hệ mà bạn không nhận ra.
Nếu bạn chọn mẫu dữ liệu mình, liệu những quan điểm tiên định của bạn có ảnh hưởng đến việc xác định những biến dự đoán nào quan trọng và phần nào của dân số nên được đại diện? Rất quan trọng để suy ngẫm về bất kỳ thiên vị cá nhân nào có thể ảnh hưởng đến đầu vào/đầu ra.
Quá trình lấy mẫu có thể làm méo mó dữ liệu? Đánh giá xem phương pháp bạn phỏng vấn người có ảnh hưởng đến câu trả lời của họ hay không; hoặc liệu các câu hỏi có gợi ý không.
Nếu việc phân tích cho thấy AI của bạn không “công bằng” theo các tiêu chí đã được thiết lập, có ba điểm mà bạn có thể giảm thiểu sự thiên vị hiện tại:
- Trên dữ liệu huấn luyện
- Trong mô hình
- Trên nhãn dự đoán
Chúng tôi khuyến nghị bạn thực hiện các quy trình giảm thiểu thiên vị càng sớm càng tốt trong chuỗi xử lý. Chúng tôi cũng khuyên bạn thử nghiệm nhiều thuật toán giảm thiểu thiên vị, vì hiệu quả của một thuật toán phụ thuộc vào đặc điểm dữ liệu. Các thuật toán giảm thiểu thiên vị cũng khác nhau về:
Các loại AI mà chúng áp dụng; hầu hết các thuật toán được đề xuất trong Bộ công cụ mã nguồn mở AI Fairness 360 là cho bộ phân loại nhị phân (tức là AI đưa ra dự đoán có hai giá trị, ví dụ: “có/không”)
Các chỉ số công bằng mà chúng hỗ trợ
Liệu thuật toán có cần bạn “tinh chỉnh” dữ liệu đầu vào hay không (trong một tình huống thực tế, bạn có thể không thể làm điều này)
Mức độ minh bạch của thuật toán, tức là mức độ giải thích được kết quả sau khi áp dụng các biện pháp giảm thiểu.
5. Đảm bảo sự giám sát của con người
Các mô hình AI ngày càng được triển khai để tăng cường và thay thế quyết định của con người. Điều đó vừa là điểm mạnh, vừa là điểm yếu của chúng. Ví dụ, xe tự lái có thể cần đưa ra quyết định quan trọng đến tính mạng mà không có sự giám sát của con người, dựa trên các giá trị đạo đức của con người. Các nhà sản xuất xe tự động đang đối mặt với nguy cơ mất kiểm soát về doanh nghiệp nếu không thể đánh giá các quyết định thuật toán để hiểu cách các quyết định được đưa ra và ảnh hưởng của chúng.
Vì vậy, con người phải được tham gia trong mọi giai đoạn của quá trình phát triển AI. Điều này sẽ giúp đảm bảo rằng hệ thống AI không làm suy yếu quyền tự chủ của con người hoặc gây ra các tác động tiêu cực khác. Nó cũng sẽ quan trọng để phát hiện định kiến và thực hiện biện pháp sửa đổi để loại bỏ nó.
6. Đảm bảo tính minh bạch
Sự giám sát của một mình con người là không đủ. Để AI được coi là có trách nhiệm, phải có mức độ cơ bản của tính minh bạch liên quan đến quá trình phát triển AI (bao gồm các yếu tố đầu vào như quy trình kỹ thuật và các quyết định của con người liên quan); quá trình và quyết định đưa ra của AI (đầu ra); và chính AI và cách nó hoạt động. Tóm lại, tính minh bạch bao gồm tính truy vết, giao tiếp và khả năng giải thích.
Tính truy vết liên quan đến việc ghi lại tất cả các bộ dữ liệu huấn luyện và thử nghiệm, các quy trình được sử dụng để huấn luyện một AI học máy và các thuật toán được sử dụng. Điều này nên bao gồm dữ liệu đầu vào cho quyết định và một nhật ký các hoạt động xử lý liên quan. Tính truy vết có thể giúp xác định nguyên nhân gây ra các quyết định AI sai lầm và xác định biện pháp sửa chữa. Nó cũng sẽ hữu ích trong bất kỳ cuộc kiểm toán nào về quyết định của AI.
Giao tiếp có nghĩa là trước tiên, hệ thống AI xác định chính nó là AI, và không giả vờ là con người. Nếu người dùng có quyền tương tác với một con người, AI nên thông báo điều này một cách rõ ràng. Nó cũng nên mở cách thông báo về khả năng và hạn chế của mình, sự tồn tại của bất kỳ vấn đề thực tế hoặc định kiến nào (như định kiến), và cách nó đưa ra quyết định.
Khả năng giải thích là thành phần về tính minh bạch được tranh luận nhiều nhất và được hiểu ít nhất. Tuy nhiên, vì các quy định quốc tế ngày càng điều chỉnh AI và yêu cầu tính minh bạch đối với các công ty trên toàn thế giới, vấn đề này xứng đáng được xem xét.
Ở mức cơ bản nhất, “khả năng giải thích” đề cập đến khả năng cho thấy cách mà AI đạt đến một quyết định cụ thể. “AI có khả năng giải thích” là AI với các kết quả đủ hiểu được đối với con người, để quyết định và ảnh hưởng của AI được chấp nhận mà không có câu hỏi. Tùy thuộc vào ngữ cảnh kinh doanh, quyền riêng tư, bảo mật, tính minh bạch thuật toán và đạo đức số có thể đòi hỏi các mức yêu cầu khác nhau về khả năng giải thích. Ví dụ:
- AI đưa ra quyết định liên quan đến con người, như từ chối một đơn xin vay tiền, có thể yêu cầu khả năng giải thích. Theo luật, nhà cung cấp thuật toán phải cung cấp cho người xin vay lý do từ chối.
- AI đưa ra quyết định trong một vòng lặp đóng, có hậu quả nghiêm trọng, như lái xe tự động, cũng cần có khả năng giải thích cao do lý do đạo đức và (có thể) pháp lý.
Tất nhiên, có những trường hợp khi thuật toán AI không nên hoàn toàn minh bạch (một công ty mất lợi thế cạnh tranh bằng cách tiết lộ bí mật độc quyền, hoặc liên quan đến dữ liệu cá nhân), và còn những trường hợp khác nơi tính minh bạch thậm chí là không thể (“thuật toán hộp đen”). Mức độ cần thiết của khả năng giải thích sẽ phụ thuộc vào ngữ cảnh và mức độ nghiêm trọng của hậu quả nếu đầu ra đó sai lầm hoặc không chính xác.
Giải thích quyết định của AI không nhất thiết phải là việc truy ngược từng bước của quá trình ra quyết định. Bạn cũng cần xem xét khán giả mục tiêu cho giải thích (các nhóm bên liên quan khác nhau yêu cầu các giải thích khác nhau) và xác định điều cần giải thích, cách thức và cho ai.
Kết luận:
Chúng ta đã đạt đến một dấu mốc quyết định, nơi những công ty hiểu cách áp dụng, triển khai, tích hợp và quản lý AI phát triển vượt trội hơn so với những công ty không làm được điều này.
Để thực sự khai thác hết giá trị mà AI mang lại, việc giải quyết sự thiếu tin tưởng và sợ hãi của một số doanh nghiệp và người tiêu dùng đối với các khuyến nghị, thông tin và quyết định dựa trên AI là rất quan trọng. Do đó, các tổ chức cần thiết lập một góc nhìn về AI có trách nhiệm ngay từ ban đầu. Một cơ quan giám sát độc lập có thể được thành lập trong tổ chức để đảm bảo tuân thủ các nguyên tắc và xử lý các biến cố và quy trình giảm thiểu nếu cần. Khi kết quả của AI đã được chứng minh là đáng tin cậy đối với các nhà phát triển, với người dùng và các cơ quan quản lý, khả năng